Hoi T-Mobile en gebruikers,
wij zijn sinds een aantal weken klant bij t-mobile thuis, maar ik kan momenteel echt niet zeggen dat we tevreden zijn over het internet. verre van zelfs.
we staan eigenlijk op het punt ziggo zakelijk internet weer (tijdelijk) terug te nemen en tmobile voor thuis maar even te parkeren..:
Met regelmaat is de verbinding slecht, en met slecht bedoel ik dan, “even” geen verbinding.
Het gaat hier om een aantal seconden per x minuten, en is dus niet continue.
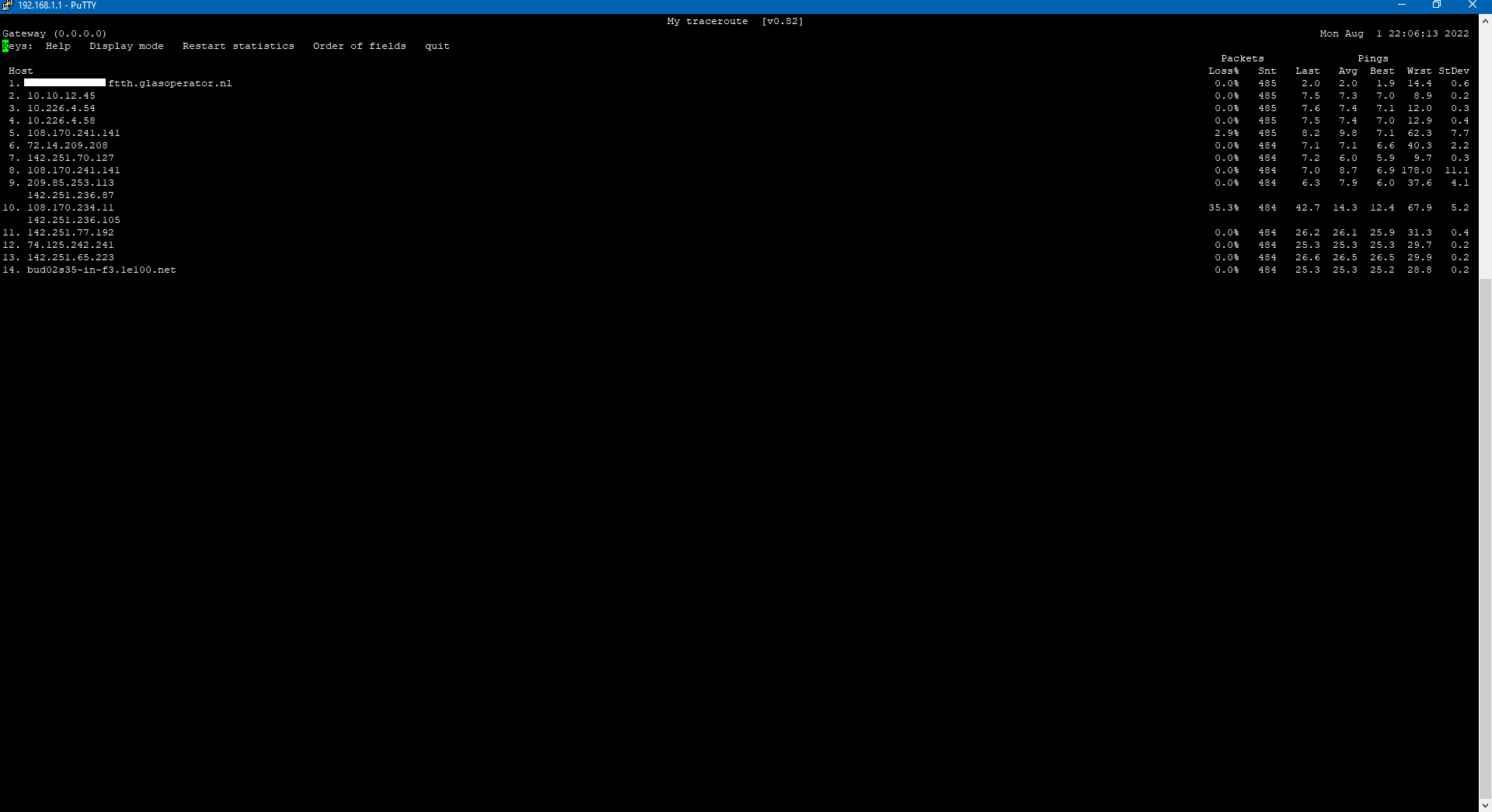
Ik ben op onderzoek uit gegaan, en daaruit is gebleken dat het probleem zit 1 van de interne (10.x) ipadressen van T-Mobile?!
Ik heb op deze ‘brakke’ momenten een aantal keer tracert gedaan, en daaruit komt steeds weer naar voren dat ik regelmatig timeouts heb in de aanvragen.
url word aangevraagd door mijn gateway (usg) > stuurt het vervolgens netjes door naar glasoperator > glasoperator stuurt het naar de 10.x ipadressen > en dan begint de ellende en gaat het dan ook regelmatig fout.
Trace tijdens een wegvallende verbinding:
tracert google.nl
Tracing route to google.nl [142.251.39.3]
over a maximum of 30 hops:
1 <1 ms <1 ms <1 ms Gateway [192.168.1.1]
2 2 ms 2 ms 2 ms x.ftth.glasoperator.nl [87.210.136.1]
3 7 ms 7 ms 7 ms 10.10.12.45
4 * * * Request timed out.
5 7 ms 7 ms 7 ms 10.226.4.58
6 37 ms 21 ms 16 ms 108.170.241.236
7 6 ms 6 ms 6 ms 72.14.209.208
8 7 ms 7 ms 7 ms 108.170.241.225
9 6 ms 6 ms 7 ms 108.170.241.236
10 8 ms 8 ms 8 ms 142.251.237.172
11 13 ms 13 ms 13 ms 142.251.237.185
12 26 ms 26 ms 26 ms 216.239.43.208
13 27 ms 27 ms 26 ms 74.125.242.225
14 25 ms 25 ms 25 ms 142.251.228.23
15 26 ms 26 ms 26 ms bud02s37-in-f3.1e100.net [142.251.39.3]
Trace tijdens een “normale” verbinding:
1 <1 ms <1 ms <1 ms Gateway [192.168.1.1]
2 2 ms 2 ms 2 ms x.ftth.glasoperator.nl [87.210.136.1]
3 7 ms 7 ms 7 ms 10.10.12.45
4 8 ms 7 ms 7 ms 10.226.4.54
5 7 ms 7 ms 7 ms 10.226.4.58
6 6 ms 6 ms 6 ms 172.253.71.201
7 6 ms 7 ms 7 ms 72.14.209.42
8 7 ms 7 ms 7 ms 142.251.70.129
9 6 ms 6 ms 6 ms 172.253.71.201
10 6 ms 6 ms 6 ms ams15s44-in-f3.1e100.net [142.251.36.3]
(PS, heb mijn hostname even vervangen voor een x)
Uiteraard is het probleem niet alleen op deze (geteste) windows pc, maar gaat het hier om het gehele internet in huis.
Voorheen dus 12 jaar lang ziggo zakelijk gehad met een vast ipadres, en daar ervaarde ik nooit deze problemen.
Het moet dus ergens zitten in dat interne 10.x netwerk van t-mobile.
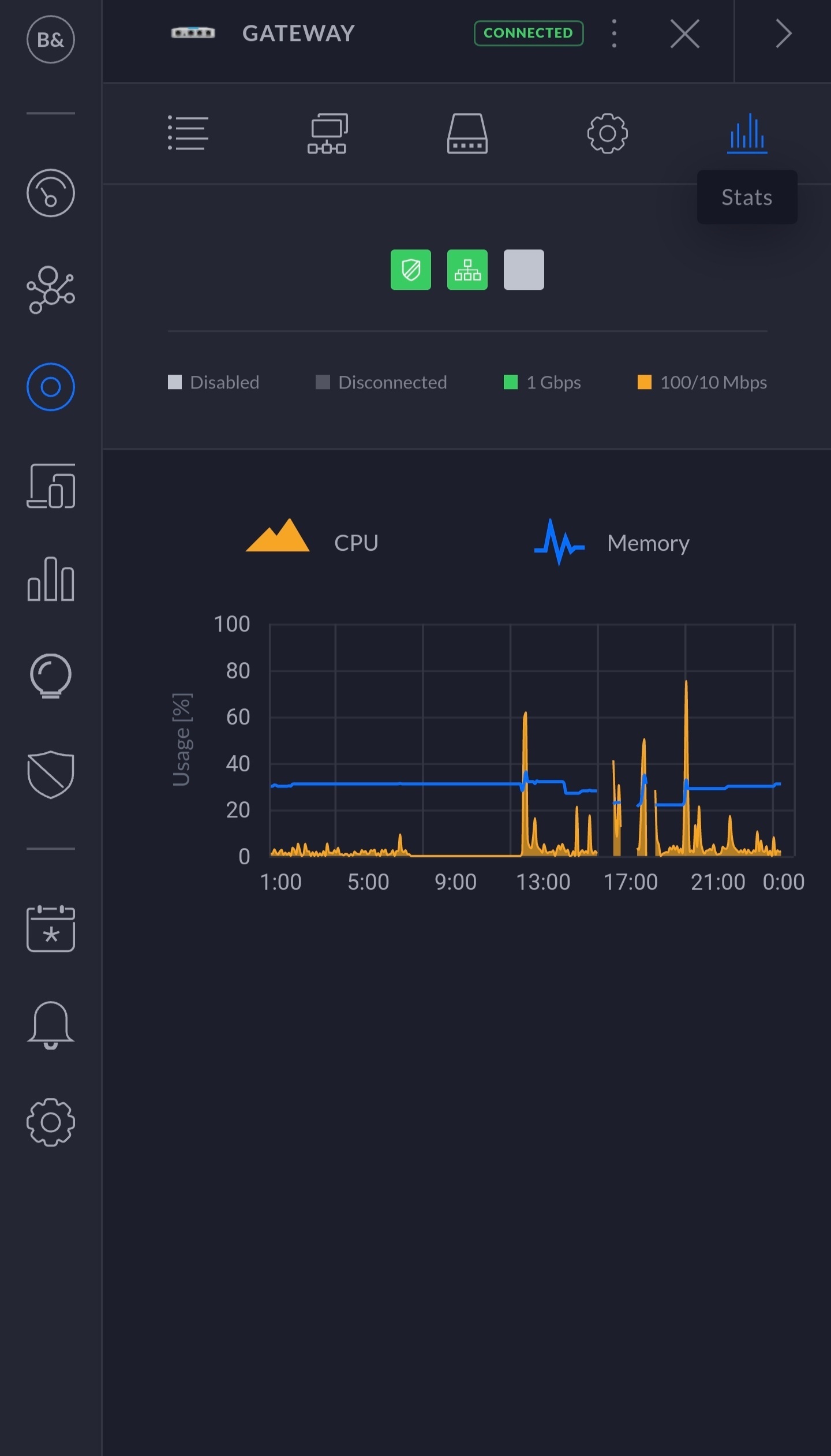
Tevens heb ik hier een lokale “uptime” server lopen dat continue, 24/7 een ping uitvoert op diverse dns servers/url's, en ook daarin zie ik met grote regelmaat korte time-outs.
Een leek zal dit wellicht niet opvallen, maar in mijn geval is de verbinding hinderlijk en heb ik (en ons huis) daar last van.
Oja, ik gebruik een unifi gateway (dus niet het modem van tmobile) direct achter de converter, maar zoals je wellicht kunt lezen heb ik intern geen problemen, en met het internet zelf ook niet, maar gaat het pas fout NA de aanvraag vanaf glasoperator.nl richting de 10.x adressen, oftewel in het interne netwerk van t-mobile..
Wellicht hebben meer mensen dit soort problemen, en/of kan dit hiermee opgelost worden?
De servers(s) waarom het gaat zijn:
10.10.12.45, 10.226.4.54 en 10.226.4.58, misschien goed om deze eens onder de loep te nemen?
Deze hebben tevens ook een enorm lange werking om de aanvragen te realiseren?
glasoperator doet het perfect binnen 1/2ms, maar daarna is het wachten op die 10.x. adressen wat (volgens mij dan weer) zorgt voor een brakke verbinding.
Ik hoop dat dit serieus word genomen en dat er wat aan gedaan kan worden want dit is niet fijn!